Арифметические операторы
Атомы +, -, *, /, mod и div — обычные атомы Пролога и могут использоваться почти в любом контексте. Указанные атомы — не встроенные предикаты, а функторы, имеющие силу только в пределах арифметических выражений. Они определены как инфиксные операторы. Эти атомы являются главными функторами в структуре, а сама структура может принимать только описанные выше формы.
Арифметический оператор выполняется следующим образом. Во-первых, вычисляются арифметические выражения по обе стороны оператора. Во-вторых, над результатом вычислений выполняется нужная операция.
Арифметические операторы определяются Пролог-системой. Если мы напишем предикат
среднее (X,Y,Z) :- Z is (X+Y)/2.
то, хотя можно определить среднее как оператор,
?- ор(250^х, среднее).
но Пролог выдаст сообщение об ошибке, если встретит выражение Z is X среднее Y.
Это произойдет потому, что Х среднее Y не образует арифметического выражения, а среднее не является арифметическим оператором, определенным в системе.
Арифметические выражения
В этой лекции показано, каким образом Пролог выполняет арифметические операции. Будут описаны арифметические операторы и их использование в выражениях, а также рассмотрены встроенные предикаты, служащие для вычисления и сравнения арифметических выражений.
Арифметическое выражение является числом или структурой. В структуру может входить одна или более компонент, таких, как числа, арифметические операторы, арифметические списковые выражения, переменная, конкретизированная арифметическим выражением, унарные функторы, функторы преобразования и арифметические функторы.
Числа. Числа и их диапазоны определяются в конкретной реализации Пролога.
Арифметические операторы. + - * / mod div
Арифметические списковые выражения. Если Х — арифметическое выражение, то список [X ] также является арифметическим выражением, например [1,2,3]. Первый элемент списка используется как операнд в выражении. Скажем, X is ([l,2,3]+5) имеет значение 6.
Арифметические списковые выражения полезны и при обработке символов, поскольку последние могут рассматриваться как небольшие целые числа. Например, символ "а" эквивалентен [97 ] и, будучи использован в выражении, вычисляется как 97. Поэтому значение выражения "р"+"А"-"а" равно 80, что соответствует коду ASCII для "Р".
Переменная, конкретизированная арифметическим выражением. Примеры: Х-5+2 и У-3*(2+А)
Унарные функторы. Примеры: +(Х) и -(У)
Функторы преобразования. В некоторых реализациях Пролога имеется арифметика с плавающей точкой, а следовательно, и функторы преобразования. Например:
float (X) преобразует целое число Х в число с плавающей точкой.
Математические функторы. Пример: квадрат(Х) объявлен как оператор и эквивалентен арифметическому выражению (Х*Х).
ATOM
Атом представляет собой произвольную последовательность символов, заключенную в одинарные кавычки. Одинарный символ кавычки, встречающийся внутри атома, записывается дважды. Когда атом выводится на печать, внешние символы кавычек обычно не печатаются. Существует несколько исключений, когда атомы необязательно записывать в кавычках. Вот эти исключения:
атом, состоящий только из чисел, букв и символа подчеркивания и начинающийся со строчной буквы;атом, состоящий целиком из специальных символов. К специальным символам относятся:+ - * / ^ = : ; ? @ $ &Заметим, что атом, начинающийся с /*, будет воспринят как начало комментария, если он не заключен в одинарные кавычки.
Как правило, в программах на Прологе используются атомы без кавычек.
Атом, который необязательно заключать в кавычки, может быть записан и в кавычках. Запись с внешними кавычками и без них определяет один и тот же атом.
Внимание: допустимы случаи, когда атом не содержит ни одного символа (так называемый 'нулевой атом') или содержит непечатаемые символы. (В Прологе имеются предикаты для построения атомов, содержащих непечатаемые или управляющие символы.) При выводе таких атомов на печать могут возникнуть ошибки.
ЧИСЛА
Большинство реализации Пролога поддерживают целые и действительные числа. Чтобы выяснить, каковы диапазоны и точность чисел, следует обратиться к руководству по конкретной реализации.
Язык программирования Пролог
Данную лекцию нужно рассматривать не как учебник по языку Пролог, а только как краткий "ликбез", который служит для иллюстрации принципов продукционного программирования, описанных выше.
КОНСТАНТЫ
Константы известны всем программистам. В Прологе константа может быть атомом или числом.
НЕКОТОРЫЕ СТАНДАРТНЫЕ ЦЕЛЕВЫЕ УТВЕРЖДЕНИЯ ДЛЯ ОБРАБОТКИ СПИСКОВ
Покажем на примерах, как можно использовать запись вида [Н | T] вместе с рекурсией для определения некоторых полезных целевых утверждений для работы со списками.
Принадлежность списку. Сформулируем задачу проверки принадлежности данного терма списку.
Граничное условие:
Терм R содержится в списке [H|T], если R=H.
Рекурсивное условие:
Терм R содержится в списке [H|T], если R содержится в списке Т.
Первый вариант записи определения на Прологе имеет вид:
содержится (R, L) :- L=[H I T], H=R. содержится(Р, L) :- L=[H|T], содержится (R, T).Цель L=[H I T] в теле обоих утверждений служит для того, чтобы разделить список L на голову и хвост.
Можно улучшить программу, если учесть тот факт, что Пролог сначала сопоставляет с целью голову утверждения, а затем пытается согласовать его тело. Новая процедура, которую мы назовем "принадлежит", определяется таким образом:
принадлежит (R, [R | Т]). принадлежит (R, [H | Т]) :- принадлежит (R, T).
На запрос
?- принадлежит(а, [а, Ь, с]).
будет получен ответ
да
на запрос
?- принадлежит(b, [a, b, с]).
- ответ
да
но на запрос
?- принадлежит(d, (a, b, c)).
Пролог дает ответ
нет
В большинстве реализации Пролога предикат принадлежит является встроенным.
Соединение двух списков. Задача присоединения списка Q к списку Р, в результате чего получается список R, формулируется следующим образом:
Граничное условие:
Присоединение списка Q к [] дает Q.
Рекурсивное условие:
Присоединение списка Q к концу списка Р выполняется так: Q присоединяется к хвосту Р, а затем спереди добавляется голова Р.
Определение можно непосредственно написать на Прологе:
соединить([],0,0). соединить(Р,Q,Р) :- Р=[НР | ТР], соединить(TP, Q, TR), R=[HP | TR].Однако, как и в предыдущем примере, воспользуемся тем, что Пролог сопоставляет с целью голову утверждения, прежде чем пытаться согласовать тело:
присоединить([] ,Q,Q). присоединить(HP | TP], Q, [HP | TR]) :- присоединить (TP, Q, TR).На запрос
?- присоединить [а, b, с], [d, e], L).
будет получен ответ
L = [a, b, c, d].
но на запрос
?- присоединить([a, b], [c, d], [e, f]).
ответом будет
нет
Часто процедура присоединить используется для получения списков, находящихся слева и справа от данного элемента:
присоединить (L [джим, р], [джек,.билл, джим, тим, джим, боб] ) . L = [джек, билл] R = [тим, джим, боб] другие решения (да/нет)? да L=[джек, билл, джим, тим] R=[боб] другие решения (да/нет)? да других решений нетИндексирование списка. Задача получения N-ro терма в списке определяется следующим образом:
Граничное условие:
Первый терм в списке [Н | Т] есть Н.
Рекурсивное условие:
N-й терм в списке [Н | Т] является (N-I)-м термом в списке Т.
Данному определению соответствует программа:
/* Граничное условие: получить ([H | Т], 1, Н). /* Рекурсивное условие: получить([Н | Т], N, У) :- М is N - 1, получить (Т, М ,Y).Построение списков из фактов. Иногда бывает полезно представить в виде списка информацию, содержащуюся в известных фактах. В большинстве реализаций Пролога есть необходимые для этого предикаты:
bagof(X,Y,L) — определяет список термов L, конкретизирующих переменную Х как аргумент предиката Y, которые делают истинным предикат Y
setof(X,Y,L) — все сказанное о предикате bagof относится и к setof, за исключением того, что список L отсортирован и из него удалены все повторения.
Если имеются факты:
собака(рекс). собака (голди). собака (фидо). собака(реке).то на запрос
?- bagof(D, co6aкa(D), L),
будет получен ответ
L=[реке, голди, фидо, рекс]
в то время как
?-setof(D, co6aкa(D), L). дает значение
L=[фидо, голди, рекc]
Пример: сложение многочленов
Теперь мы достаточно подготовлены к тому, чтобы использовать списки для решения задач. Вопрос, которым мы займемся, — представление и сложение многочленов.
Представление многочленов. Посмотрим, как можно представить многочлен вида
Р(х)=3+3х-4х^3+2х^9
Q(х)=4х+х^2-3х^3+7х^4+8х^5
Заметим, что каждое подвыражение (такое, как Зх ^3, Зх, 3) имеет самое большее две переменные компоненты: число, стоящее перед х, называемое коэффициентом, и число, стоящее после ^ - степень. Следовательно, подвыражение представляется термом
х(Коэффициент, Степень)
Так, 5х^2 записывается как х(5,2), х^З представляется как х(1,3), а поскольку х^0 равно 1, подвыражению 5 соответствует терм х(5,0).
Теперь запишем многочлен в виде списка. Приведенный выше многочлен Р(х), например, будет выглядеть следующим образом:
[x(3, 0), '+', x(3, l), '-', x(4, 3), '+', x(2, 9)]
Воспользуемся тем, что многочлен
3 + 3х - 4х^3 + 2х^9
допускает замену на эквивалентный
3 + 3х + (-4)х^3 + 2х^9 Тогда он выражается списком:
[х(3, 0), '+', х(3, 1), '+', х(-4, 3), '+', х(2, 9)]
В такой записи между термами всегда стоят знаки '+'. Следовательно, их можно опустить, и многочлен принимает окончательный вид:
[х(3, 0), х(3, 1), х(-4, 3), х(2, 9)]
Подразумевается, что между всеми термами списка стоят знаки '+'. Представлением многочлена Q(x) будет
[х(4, 1), х(1, 2), х(-3, 3), х(7, 4), х(8, 5)]
Сложение многочленов. Теперь напишем целевые утверждения для сложения двух многочленов. Сложение многочленов
3-2х^2+4х^3+6х^6
-1+3х^2-4х^3
в результате дает
2+х^2+6х^6
Аргументами целевого утверждения являются многочлены, представленные в виде списков. Ответ будет получен также в виде списка.
Сложение многочлена Р с многочленом Q осуществляется следующим образом.
Граничное условие:
Р, складываемый с [], дает Р.
[], складываемый с Q, дает Q.
Рекурсивное условие:
При сложении Р с Q, в результате чего получается многочлен R, возможны 4 случая:
степень первого терма в Р меньше, чем степень первого терма в Q. В этом случае первый терм многочлена Р образует первый терм в R, а хвост R получается при прибавлении хвоста Р к Q. Например, если Р и Q имеют вид
Р(х)=3х^2+5х^3
Q(x)=4x^3+3x^4
то первый терм R(x) равен 3х^2 (первому терму в Р(х)). Хвост R(x) равен 9х^3+3х^4, т.е. результату сложения Q(x) и хвоста Р(х);
степень первого терма в Р больше степени первого терма в Q. В данном случае первый терм в Q образует первый терм в R, а хвост R получается при прибавлении Р к хвосту Q. Например, если
Р(х)=2х^3+5х^'4
Q(x)=3x^3-x^4
то первый терм R(x) равен 3х^2 (первому терму в Q(x)), а хвост R(x) равен 2х^3+4х^4 (результату сложения Р(х) и хвоста Q(x));
степени первых термов в Р и Q равны, а сумма их коэффициентов отлична от нуля. В таком случае первый терм в R имеет коэффициент, равный сумме коэффициентов первых термов в Р и Q. Степень первого терма в R равна степени первого терма в Р (или Q). Хвост R получается при сложении хвоста Р и хвоста Q. Например, если Р и Q имеют вид
Р(х)=2х+3х^3
Q(x)=3x+4x^4
то первый терм многочлена R (х) равен 5х (результату сложения первого терма в Р(х) с первым термом в Q(x)). Хвост R(x) равен 3х^3+4х^4 (результату сложения хвоста Р(х) и хвоста Q(x));
степени первых термов в Р и Q одинаковы, но сумма коэффициентов равна нулю. В данном случае многочлен R равен результату сложения хвоста Р с хвостом Q. Например, если
р(х)=2+2х
Q(x)=2-3x^2
то
R(x)=2x-3x^2
(это результат сложения хвостов многочленов Р (х) и Q (х)).Рассмотренный процесс сложения многочленов можно непосредственно записать на языке Пролог.
/* Граничные условия слож_мн([], Q Q). слож_мн(P, [], P). /* Рекурсивное условие /* (a) слож_мн([x(Pc, Pp)|Pt], [x(Qc, Qp)|Qt], [x(Pc,Pp)IRt]) :- PpQp, слож_мн(Рt, [х(Qс,Qр) | Qt], Rt). /*(б) слож_мн([x(Pc, Pp) | Pt], [x(Qc, Qp) | Qt], [x(Qc, Qp) | Rt]) :- PpQp, слож_мн([x(Pc, Pp) | Pt], Qt, Rt). /*(в) слож_мн([x(Pc, Pp) | Pt], [х(Qc,Pp) | Qt], [x(Rc, Pp) | Rt]) :- Rc is Pc+Qc, Rc =\= 0, слож_мн(Pt, Qt,Rt). /*(r) слож_мн([х(Рс, Рр) | Pt], [x(Qc.Pp) | Qt], Rt) :- Re is Pc+Qc, Rc =:= 0, слож_мн(Pt, Qt, Rt).Заметим, что в двух последних утверждениях проверка на равенство осуществляется следующим образом: степени первых термов складываемых утверждений обозначает одна и та же переменная Pp.
Списки как термы. В начале лекции мы упомянули о том, что список представляется с помощью терма. Такой терм имеет функтор '.', два аргумента и определяется рекурсивно. Первый аргумент является головой списка, а второй — термом, обозначающим хвост списка. Пустой список обозначается []. Тогда список [а, b] эквивалентен терму.(а,.(b, [])).
Таким образом, из списков, как и из термов, можно создавать вложенные структуры. Поэтому выражение
[[a, b], [c, d], [a], a]
есть правильно записанный список, и на запрос
?- [Н | Т]=[[а, b], с].
Пролог дает ответ
Н=[а, b] Т=[с]

ОБЛАСТЬ ДЕЙСТВИЯ ПЕРЕМЕННЫХ
Областью действия переменной является утверждение. В пределах утверждения одно и то же имя принадлежит одной и той же переменной. Два утверждения могут использовать одно имя переменной совершенно различным образом. Правило определения области действия переменной справедливо также в случае рекурсии и в том случае, когда несколько утверждений имеют одну и ту же головную цель. Этот вопрос будет рассмотрен далее.
Единственным исключением из правила определения области действия переменных является анонимная переменная, например, "_" в цели любит(Х,_). Каждая анонимная переменная есть отдельная сущность. Она применяется тогда, когда конкретное значение переменной несущественно для данного утверждения. Таким образом, каждая анонимная переменная четко отличается от всех других анонимных переменных в утверждении.
Переменные, отличные от анонимных, называются именованными, а неконкретизированные (переменные, которым не было присвоено значение) называются свободными.
ПЕРЕМЕННЫЕ
Понятие переменной в Прологе отличается от принятого во многих языках программирования. Переменная не рассматривается как выделенный участок памяти. Она служит для обозначения объекта, на который нельзя сослаться по имени. Переменную можно считать локальным именем для некоторого объекта.
Синтаксис переменной довольно прост. Она должна начинаться с прописной буквы или символа подчеркивания и содержать только символы букв, цифр и подчеркивания.
Переменная, состоящая только из символа подчеркивания, называется анонимной и используется в том случае, если имя переменной несущественно.
СИНТАКСИС ОПЕРАТОРОВ
Структуры арности 1 и 2 могут быть записаны в операторной форме, если атом, используемый как главный функтор в структуре, объявить оператором (см. лек. 6).
СИНТАКСИС СПИСКОВ
В сущности, список есть не что иное, как некоторая структура арности 2. Данная структура становится интересной и чрезвычайно полезной в случае, когда вторая компонента тоже является списком. Вследствие важности таких структур в Прологе имеются специальные средства для записи списков.
СИНТАКСИС СТРОК
Строка определяется как список кодов символов. Коды символов имеют особое значение в языках программирования. Они выступают как средство связи компьютера с внешним миром. В большинстве реализации Пролога существует специальный синтаксис для записи строк. Он подобен синтаксису атомов. Строкой является любая последовательность символов, которые могут быть напечатаны (кроме двойных кавычек), заключенная в двойные кавычки. Двойные кавычки в пределах строки записываются дважды "".
В некоторых реализациях Пролога строки рассматриваются как определенный тип объектов подобно атомам или спискам. Для их обработки вводятся специальные встроенные предикаты. В других реализациях строки обрабатываются в точности так же, как списки, при этом используются встроенные предикаты для обработки списков. Поскольку все строки могут быть определены как атомы или как списки целых чисел, и понятие строки является чисто синтаксическим, мы не будем более к нему возвращаться.
СЛОЖНЫЕ ТЕРМЫ, ИЛИ СТРУКТУРЫ
Структура состоит из атома, называемого главным функтором, и последовательности термов, называемых компонентами структуры. Компоненты разделяются запятыми и заключаются в круглые скобки.
Приведем примеры структурированных термов:
собака(рекс), родитель(Х,У).
Число компонент в структуре называется арностью структуры. Так, в данном примере структура собака имеет арность 1 (записывается как собака/1), а структура родитель — арность 2 (родитель/2). Заметим, что атом можно рассматривать как структуру арности 0.
Для некоторых типов структур допустимо использование альтернативных форм синтаксиса. Это синтаксис операторов для структур арности 1 и 2, синтаксис списков для структур в форме списков и синтаксис строк для структур, являющихся списками кодов символов.
СПИСКОВАЯ ФОРМА ЗАПИСИ
Задачи, связанные с обработкой списков, на практике встречаются очень часто. Скажем, нам понадобилось составить список студентов, находящихся в аудитории. С помощью Пролога мы можем определить список как последовательность термов, заключенных в скобки. Приведем примеры правильно построенных списков Пролога:
[джек, джон, фред, джилл, джон]
[имя (джон, смит), возраст (джек, 24), X]
[Х.У.дата (12,январь, 1986) ,Х]
[]
Запись [H|T] определяет список, полученный добавлением Н в начало списка Т. Говорят, что Н — голова, а Т — хвост списка [HIT]. На вопрос
?-L=[a | [b, c, d]]. будет получен ответ L=[a, b, c, d]
а на запрос ?-L= [a, b, c, d], L2=[2 | L]. — ответ L=[a, b, c, d], L2- [2, a, b, c, d]
Запись [Н | Т] используется для того, чтобы определить голову и хвост списка. Так, запрос ?- [X | Y]=[a, b, c]. дает Х=а, Y=[b, c]
Заметим, что употребление имен переменных Н и Т необязательно. Кроме записи вида [H|T], для выборки термов используются переменные. Запрос
?-[a, X, Y]=[a, b, c].
определит значения
X=b Y=c
а запрос
?- [личность(Х) | Т]=[личность(джон), а, b].
значения
Х=джон Т=[а, Ь]
Сравнение результатов арифметических выражений
Системные предикаты =:=, =\=, >, <, >= и <= определены как инфиксные операторы и применяются для сравнения результатов двух арифметических выражений.
Для предиката @ доказательство целевого утверждения X@Y заканчивается успехом, если результаты вычисления арифметических выражений Х и Y находятся в таком отношении друг к другу, которое задается предикатом @.
Такое целевое утверждение не имеет побочных эффектов и не может быть согласовано вновь. Если Х или Y — не арифметические выражения, возникает ошибка.
С помощью предикатов описываются следующие отношения:
Х =:= Y - Х равно Y
Х =\= Y - Х не равно Y
Х < Y - Х меньше Y
Х > Y - Х больше Y
Х <= Y - Х меньше или равно Y
Х >= Y - Х больше или равно Y
Использование предикатов иллюстрируют такие примеры:
а > 5 - заканчивается неудачей
5+2+7 > 5+2 - заканчивается успехом
3+2 =:= 5 - заканчивается успехом
3+2 < 5 - заканчивается неудачей
2 + 1 =\= 1 - заканчивается успехом
N > 3 - заканчивается успехом, если N больше 3, и неудачей в противном случае
Структуры данных
Термы Пролога позволяют выразить самую разнообразную информацию. В настоящей лекции мы рассмотрим два вида широко используемых структур данных: списки и бинарные деревья, и покажем, как они представляются термами Пролога.
ТЕРМЫ
Объекты данных в Прологе называются термами. Терм может быть константой, переменной или составным термом (структурой). Константами являются целые и действительные числа, например:
0, -l, 123.4, 0.23E-5,
(некоторые реализации Пролога не поддерживают действительные числа).
К константам относятся также атомы, такие, как:
голди, а, атом, +, :, 'Фред Блогс', [].
Атом есть любая последовательность символов, заключенная в одинарные кавычки. Кавычки опускаются, если и без них атом можно отличить от символов, используемых для обозначения переменных. Приведем еще несколько примеров атомов:
abcd, фред, ':', Джо.
Полный синтаксис атомов описан ниже.
Как и в других языках программирования, константы обозначают конкретные элементарные объекты, а все другие типы данных в Прологе составлены из сочетаний констант и переменных.
Имена переменных начинаются с заглавных букв или с символа подчеркивания "_". Примеры переменных:
X, Переменная, _3, _переменная.
Если переменная используется только один раз, необязательно называть ее. Она может быть записана как анонимная переменная, состоящая из одного символа подчеркивания "_". Переменные, подобно атомам, являются элементарными объектами языка Пролог.
Завершает список синтаксических единиц сложный терм, или структура. Все, что не может быть отнесено к переменной или константе, называется сложным термом. Следовательно, сложный терм состоит из констант и переменных.
Теперь перейдем к более детальному описанию термов.
Унификация
Одним из наиболее важных аспектов программирования на Прологе являются понятия унификации (отождествления) и конкретизации переменных.
Пролог пытается отождествить термы при доказательстве, или согласовании, целевого утверждения. Например, в программе из лек. 1 для согласования запроса ?- собака(Х) целевое утверждение собака (X) было отождествлено с фактом собака (реке), в результате чего переменная Х стала конкретизированной: Х= рекc.
Переменные, входящие в утверждения, отождествляются особым образом — сопоставляются. Факт доказывается для всех значений переменной (переменных). Правило доказывается для всех значений переменных в головном целевом утверждении при условии, что хвостовые целевые утверждения доказаны. Предполагается, что переменные в фактах и головных целевых утверждениях связаны квантором всеобщности. Переменные принимают конкретные значения на время доказательства целевого утверждения.
В том случае, когда переменные содержатся только в хвостовых целевых утверждениях, правило считается доказанным, если хвостовое целевое утверждение истинно для одного или более значений переменных. Переменные, содержащиеся только в хвостовых целевых утверждениях, связаны квантором существования. Таким образом, они принимают конкретные значения на то время, когда целевое утверждение, в котором переменные были согласованы, остается доказанным.
Терм Х сопоставляется с термом Y по следующим правилам. Если Х и Y — константы, то они сопоставимы, только если они одинаковы. Если Х является константой или структурой, а Y — неконкретизированной переменной, то Х и Y сопоставимы и Y принимает значение Х (и наоборот). Если Х и Y — структуры, то они сопоставимы тогда и только тогда, когда у них одни и те же главный функтор и арность и каждая из их соответствующих компонент сопоставима. Если Х и Y — неконкретизированные (свободные) переменные, то они сопоставимы, в этом случае говорят, что они сцеплены. В (Таблица 7.1) приведены примеры отождествимых и неотождествимых термов.
| джек(Х) | джек (человек) | да: Х=человек |
| джек (личность) | джек (человек) | нет |
| джек(Х,Х) | джек(23,23) | да: Х=23 |
| джек(Х.Х) | джек (12,23) | нет |
| джек( . ) | джек(12,23) | да |
| f(Y,Z) | Х | да: X=f(Y,Z) |
| Х | Z | да: X=Z |
p>Заметим, что Пролог находит наиболее общий унификатор термов. В последнем примере (табл.7.1) существует бесконечное число унификаторов:
X-1, Z-2; X-2, Z-2; ....
но Пролог находит наиболее общий: Х=Z.
Следует сказать, что в большинстве реализаций Пролога для повышения эффективности его работы допускается существование циклических унификаторов. Например, попытка отождествить термы f(X) и Х приведет к циклическому унификатору X=f(X), который определяет бесконечный терм f(f(f(f(f(...))))). В программе это иногда вызывает бесконечный цикл.
Возможность отождествления двух термов проверяется с помощью оператора =.
Ответом на запрос
?- 3+2=5.
будет
нет
так как термы не отождествимы (оператор не вычисляет значения своих аргументов), но попытка доказать
?-строка(поз(Х)) -строка(поз(23)).
закончится успехом при
Х=23.
Унификация часто используется для доступа к подкомпонентам термов. Так, в вышеприведенном примере Х конкретизируется первой компонентой терма поз(23), который в свою очередь является компонентой терма строка.
Бывают случаи, когда надо проверить, идентичны ли два терма. Выполнение оператора = = заканчивается успехом, если его аргументы — идентичные термы. Следовательно, запрос
?-строка(поз(Х)) --строка (поз (23)).
дает ответ
нет
поскольку подтерм Х в левой части (X — свободная переменная) не идентичен подтерму 23 в правой части, Однако запрос
?- строка (поз (23)) --строка (поз (23)).
дает ответ
да
Отрицания операторов = и - = записываются как \= и \= = соответственно.
УТВЕРЖДЕНИЯ
Программа на Прологе есть совокупность утверждений. Утверждения состоят из целей и хранятся в базе данных Пролога. Таким образом, база данных Пролога может рассматриваться как программа на Прологе. В конце утверждения ставится точка ".". Иногда утверждение называется предложением.
Основная операция Пролога — доказательство целей, входящих в утверждение.
Существуют два типа утверждений:
факт — это одиночная цель, которая, безусловно, истинна;правило — состоит из одной головной цели и одной или более хвостовых целей, которые истинны при некоторых условиях.Правило обычно имеет несколько хвостовых целей в форме конъюнкции целей.
Конъюнкцию можно рассматривать как логическую функцию И. Таким образом, правило согласовано, если согласованы все его хвостовые цели.
Примеры фактов:
собака(реке). родитель(голди.рекс).
Примеры правил:
собака (X) :- родитель (X.Y),собака (Y). человек(Х) :-мужчина(Х).
Разница между правилами и фактами чисто семантическая. Хотя для правил мы используем синтаксис операторов (более подробное рассмотрение операторного и процедурного синтаксисов выходит за рамки нашего курса), нет никакого синтаксического различия между правилом и фактом.
Так, правило
собака (X) :- родитель(Х,У),собака(У). может быть задано как
:-собака (X) ',' родитель(Х.У) .собака (Y).
Запись верна, поскольку :- является оператором "при условии, что", а ',' — это оператор конъюнкции. Однако удобнее записывать это как
собака (X) :-родитель (X.Y),собака (Y).
и читать следующим образом: " Х — собака при условии, что родителем Х является Y и Y — собака".
Структуру иногда изображают в виде дерева, число ветвей КОТОРОГО равно арности структуры.

Язык Пролог не предназначен для
Язык Пролог не предназначен для программирования задач с большим количеством арифметических операций. Для этого используются процедурные языки программирования. Однако в любую Пролог-систему включаются все обычные арифметические операторы:
+ сложение — вычитание * умножение / деление mod остаток от деления целых чисел div целочисленное деление В некоторых реализациях языка Пролог присутствует более широкий набор встроенных арифметических операторов.
Диапазоны чисел, входящих в арифметические выражения, зависят от реализации Пролога. Например, система ICLPROLOG оперирует целыми числами со знаком в диапазоне
–8388606 ... 8388607
ВВОД программ
Введение списка утверждений в Пролог-систему осуществляется с помощью встроенного предиката consult. Аргументом предиката consult является атом, который обычно интерпретируется системой как имя файла, содержащего текст программы на Прологе. Файл открывается, и его содержимое записывается в базу данных. Если в файле встречаются управляющие команды, они сразу же выполняются. Возможен случай, когда файл не содержит ничего, кроме управляющих команд для загрузки других файлов. Для ввода утверждений с терминала в большинстве реализации Пролога имеется специальный атом, обычно user. С его помощью утверждения записываются в базу данных, а управляющие команды выполняются немедленно.
Помимо предиката consult, в Прологе существует предикат reconsult. Он работает аналогичным образом. Но перед добавлением утверждений к базе данных из нее автоматически удаляются те утверждения, головные цели которых сопоставимы с целями, содержащимися в файле перезагрузки. Такой механизм позволяет вводить изменения в базу данных. В Прологе имеются и другие методы добавления и удаления утверждений из базы данных. Некоторые реализации языка поддерживают модульную структуру, позволяющую разрабатывать модульные программы.
В заключение раздела дадим формальное определение синтаксиса Пролога, используя форму записи Бэкуса-Наура, иногда называемую бэкусовской нормальной формой (БНФ).
запрос ::- голова утверждения правило ::– голова утверждения :- хвост утверждения факт ::- голова утверждения голова утверждения ::-атом | структура хвост утверждения ::- атом структура, термы ::-терм [,термы] терм ::- число | переменная | атом | структура структура ::-атом (термы)Данное определение синтаксиса не включает операторную, списковую и строковую формы записи. Полное определение дано в приложении А. Однако, любая программа на Прологе может быть написана с использованием вышеприведенного синтаксиса. Специальные формы только упрощают понимание программы. Как мы видим, синтаксис Пролога не требует пространного объяснения. Но для написания хороших программ необходимо глубокое понимание языка.
Вычисление арифметических выражений
В Прологе не допускаются присваивания вида Сумма=2+4.
Выражение такого типа вычисляется только с помощью системного предиката is, например:
Сумма is 2 + 4.
Предикат is определен как инфиксный оператор. Его левый аргумент — или число, или неконкретизированная переменная, а правый аргумент — арифметическое выражение.
Попытка доказательства целевого утверждения Х is Y заканчивается успехом в одном из следующих случаев:
Х — неконкретизированная переменная, а результат вычисления выражения Y есть число;Х — число, которое равно результату вычисления выражения Y. Цель Х is Y не имеет побочных эффектов и не может быть согласована вновь. Если Х не является неконкретизированной переменной или числом либо если Y — не арифметическое выражение, возникает ошибка.Примеры:
D is 10- 5 заканчивается успехом и D становится равным 5 4 is 2 * 4 - 4 заканчивается успехом 2 * 4 - 4 is 4 заканчивается неудачей a is 3 + 3 заканчивается неудачей X is 4 + а заканчивается неудачей 2 is 4 - X заканчивается неудачейОбратите внимание, что предикат is требует, чтобы его первый аргумент был числом или неконкретизированной переменной. Поэтому М - 2 is 3 записано неверно. Предикат is не является встроенным решателем уравнений.
ЗАПРОСЫ
После записи утверждений в базу данных вычисления могут быть инициированы вводом запроса.
Запрос выглядит так же, как и целевое утверждение, образуется и обрабатывается по тем же правилам, но он не входит в базу данных (программу). В Прологе вычислительная часть программы и данные имеют одинаковый синтаксис. Программа обладает как декларативной, так и процедурной семантикой. Мы отложим обсуждение этого вопроса до последующих лекций. Запрос обозначается в Прологе утверждением ?-, имеющим арность 1. Обычно запрос записывается в операторной форме: за знаком ?- следует ряд хвостовых целевых утверждений (чаще всего в виде конъюнкции).
Приведем примеры запросов:
?-собака(X). ?- родитель(Х.У),собака (Y).
или, иначе,
'?-'(собака(Х)) С?-') ','(родитель(Х„У",собака (Y)).
Последняя запись неудобна тем, что разделитель аргументов в структуре совпадает с символом конъюнкции. Программисту нужно помнить о различных значениях символа ','.
Запрос иногда называют управляющей командой (директивой), так как он требует от Пролог-системы выполнения некоторых действий. Во многих реализациях Пролога для управляющей команды используется альтернативный символ, а символ ?- обозначает приглашение верхнего уровня интерпретатора Пролога. Альтернативным символом является :-. Таким образом,
:-write(co6aкa).
- это управляющая команда, в результате выполнения которой печатается атом собака. Управляющие команды будут рассмотрены ниже при описании ввода программ.
Иерархия типов
Иерархия типов и подтипов является стандартной характеристикой семантических сетей. Иерархия может включать сущности: ТАКСА < СОБАКА < ПЛОТОЯДНОЕ < ЖИВОТНОЕ < ЖИВОЕ СУЩЕСТВО < ФИЗИЧЕСКИЙ ОБЪЕКТ < СУЩНОСТЬ. Они также могут включать в себя события: ЖЕРТВОВАТЬ < ДАВАТЬ < ДЕЙСТВИЕ < СОБЫТИЕ или состояния: ЭКСТАЗ < СЧАСТЬЕ < ЭМОЦИОНАЛЬНОЕ СОCТОЯНИЕ < СОСТОЯНИЕ. Иерархия Аристотеля включала в себя 10 основных категорий: субстанция, количество, качество, отношение, место, время, состояние, активность и пассивность. Некоторые учение дополнили его своими категориями.
Символ < между более общим и более частным символом читается как: "Х-тип/подтип У".
Термин "иерархия" обычно обозначает частичное упорядочение, где одни типы являются более общими, чем другие. Упорядочение является частичным, потому, что многие типы просто не подлежат сравнению между собой. Сравним HOUSE<DOG и DOG<HOUSE бессмысленны, если их сравнивать, однако слово DOGHOUSE является подтипом HOUSE, но не DOG. Рассмотрим некоторые виды графов:
Ацикличный граф. Любое частичное упорядочение может быть изображено, как граф без циклов. Такой граф имеет ветви, которые расходятся и сходятся вместе опять, что позволяет некоторым узлам иметь несколько узлов-родителей. Иногда такой тип графа называют путанным.
Деревья. Самым распространенным видом иерархии является граф с одной вершиной. В такого рода графах налагаются ограничения на ацикличные графы: вершина графа представляет собой один общий тип, и каждый другой тип Х имеет лишь одного родителя У.
Решетка. В отличие от деревьев узлы в решетке могут иметь несколько узлов родителей. Однако здесь налагаются другие ограничения: любая пара типов Х и У как минимум должна иметь общий гипертип ХиУ и подтип ХилиУ. Вследствие этого ограничения решетка выглядит, как дерево, имеющее по главной вершине с каждого конца. Вместо всего одной вершины решетка имеет одну вершину, которая является гипертипом всех категорий, и другую вершину, которая является подтипом всех типов.
Элементы нечеткой логики
Как известно, классическая логика оперирует только с двумя значениями: истина и ложь. Однако этими двумя значениями довольно сложно представить (можно, но громоздко) большое количество реальных задач. Поэтому для их решения был разработан специальный математический аппарат, называемый нечеткой логикой. Основным отличием нечеткой логики от классической, как явствует из названия, является наличие не только двух классических состояний (значений), но и промежуточных:

Соответственно, вводятся расширения базовых операций логического умножения, сложения и отрицания (сравните с соответствующими операциями теории вероятностей):
a I b = min{a,b}
a Y b = max{a,b}

Как можно легко заметить, при использовании только классических состояний (ложь-0, истина-1) мы приходим к классическим законам логики.
Нечеткое логическое управление может использоваться, чтобы осуществлять разнообразные интеллектуальные функции, в самых разнообразных электронных товарах и домашних приборах, в автоэлектронике, управлении производственными процессами и автоматизации.
Механизм возврата
При попытке согласования целевого утверждения Пролог выбирает первое из тех утверждений, голова которых сопоставима с целевым утверждением. Если удастся согласовать тело утверждения, то целевое утверждение согласовано. Если нет, то Пролог переходит к следующему утверждению, голова которого сопоставима с целевым утверждением, и так далее до тех пор, пока целевое утверждение не будет согласовано или не будет доказано, что оно не согласуется с базой данных.
В качестве примера рассмотрим утверждения:
меньше(X.Y) :- XY, write(X), write ('меньше, чем'),write(Y). меньше(Х.У) :- XY, write(Y), write ('меньше, 4CM'),write(X).Целевое утверждение
?- меньше (5, 2).
сопоставляется с головой первого утверждения при Х=5 и У=2. Однако не удается согласовать первый член конъюнкции в теле утверждения X<Y. Значит, Пролог нс может использовать первое утверждение для согласования целевого утверждения меньше(5, 2). Тогда Пролог переходит к следующему утверждению, голова которого сопоставима с целевым утверждением. В нашем случае это второе утверждение. При значениях переменных Х=5 и Y=2 тело утверждения согласуется. Целевое утверждение меньше(5,2) доказано, и Пролог выдает сообщение "2 меньше, чем 5". Запрос
?-меньше (2, 2).
сопоставляется с головой первого утверждения, но тело утверждения согласовать не удается. Затем происходит сопоставление с головой второго утверждения, но согласовать тело опять-таки оказывается невозможно. Поэтому попытка доказательства целевого утверждения меньше(2, 2) заканчивается неудачей.
Такой процесс согласования целевого утверждения путем прямого продвижения по программе мы называем прямой трассировкой (forward tracking). Даже если целевое утверждение согласовано, с помощью прямой трассировки мы можем попытаться получить другие варианты его доказательства, т.е. вновь согласовать целевое утверждение.
Пролог производит доказательство конъюнкции целевых утверждений слева направо. При этом может встретиться целевое утверждение, согласовать которое не удается. Если такое случается, то происходит смещение влево до тех пор, пока не будет найдено целевое утверждение, которое может быть вновь согласовано, или не будут исчерпаны все предшествующие целевые утверждения. Если слева нет целевых утверждений, то конъюнкцию целевых утверждений согласовать нельзя. Однако, если предшествующее целевое утверждение может быть согласовано вновь, Пролог возобновляет процесс доказательства целевых утверждений слева направо, начиная со следующего справа целевого утверждения. Описанный процесс смещения влево для повторного согласования целевого утверждения и возвращения вправо носит название механизма возврата.
Механизм возврата и процедурная семантика
При согласовании целевого утверждения в Прологе используется метод, известный под названием механизма возврата. В этой лекции мы показываем, в каких случаях применяется механизм возврата, как он работает и как им пользоваться. Здесь описывается декларативная и процедурная семантика процедур Пролога. Завершается лекция обсуждением вопросов эффективности.
Наследование.
Основным свойством иерархии является возможность наследования подтипами качеств гипертипов: все характеристики, которые присущи ЖИВОТНОМУ, также присущи МЛЕКОПИТАЮЩЕМУСЯ, РЫБЕ и ПТИЦЕ. В основе теории наследования лежит теория силлогизмов Аристотеля: Если А — характеристика В, а В — х-ка С, то А — хар-ка всех С.
Преимущества иерархии и наследования:
Иерархия типов является отличной структурой для индексирования базы знаний и ее эффективной организации.Следование по какой-либо ветви с помощью иерархии осуществляется гораздо быстрее.Представление бинарных деревьев
Бинарное дерево определяется рекурсивно как имеющее левое поддерево, корень и правое поддерево . Левое и правое поддеревья сами являются бинарными деревьями. На рис. 8.1 показан пример бинарного дерева.

Рис. 8.1. Бинарное дерево.
Такие деревья можно представить термами вида
бд(Лд, К, Пд),
где Лд — левое поддерево, К — корень, а Пд — правое поддерево. Для обозначения пустого бинарного дерева будем использовать атом nil. Бинарное дерево на рис.8.1 имеет левое поддерево бд(бд(nil, d, nil), b, бд(nil, е, nil)) правое поддерево бд(nil,с, nil) и записывается целиком как бд(бд(бд(nil,d, nil), b, бд(nil,е, nil)), а, бд(nil, с, nil)).
Представление множеств с помощью бинарных деревьев
Описание множеств в виде списков позволяет использовать для множеств целевое утверждение принадлежит, определенное ранее для списков.
Однако для множеств, состоящих из большого числа элементов, списковые целевые утверждения становятся неэффективными. Рассмотрим, например, как целевое утверждение "принадлежит" (см. предыдущий разд.) позволяет моделировать принадлежность множеству. Пусть L — список, описывающий множество из первых 1024 натуральных чисел. Тогда при ответе на запрос
?- принадлежит(3000, b).
Прологу придется проверить все 1024 числа, прежде чем заключить, что такого числа нет:
нет
Представление множества бинарным деревом позволяет добиться лучшего результата. При этом бинарное дерево должно быть упорядочено таким образом, чтобы любой элемент в левом поддереве был меньше, чем значение корня, а любой элемент в правом поддереве — больше. Поскольку мы определили поддерево как бинарное дерево, такое упорядочение применяется по всем поддеревьям. На Рис. 8.2 приведен пример упорядоченного бинарного дерева.
Рис. 8.2. Упорядоченное бинарное дерево
Обратите внимание, что упорядочение приводит не к единственному варианту представления множества с помощью дерева. Например, на рис. 8.3 изображено то же множество, что и на рис. 8.2
Будем называть линейным представление такого вида, как на рис. 8.3, и сбалансированным — такое, как на рис. 8.2

Рис. 8.3. Линейное представление
Моделирование принадлежности множеству. Имея множество, описанное бинарным деревом, мы можем моделировать принадлежность множеству с помощью целевого утверждения принадлежит_дереву. При этом используется оператор @<, выражающий отношение "меньше, чем", и оператор @>, выражающий отношение "больше, чем".
/* Граничное условие: Х принадлежит /* дереву, если Х является корнем. принадлежит_дереву(Х, бд(Лд, Х, Пд)), /* Рекурсивные условия /* Х принадлежит дереву, если Х больше /* значении корня и находится в правом /* поддереве: принадлежит_дереву(Х, бд(Лд, У, Пд)) :- X@Y, припадлежит_дереву(Х, Пд). /* Х принадлежит дереву, если Х меньше /* значения корня и находится в левом /* поддереве: принадлежит_дереву(Х, бд(Лд ,У ,Пд)) :-X@Y, принадлежит_дереву(Х, Лд).Если множество из первых 1024 чисел описать с помощью сбалансированного бинарного дерева Т, то при ответе на запрос
?- принадлежит_дереву(3000, Т).
Пролог сравнит число 3000 не более чем с 11 элементами множества. прежде чем ответит:
нет
Конечно, если Т имеет линейное представление, то потребуется сравнение 3000 с 1024 элементами множества.
Построение бинарного дерева. Задача создания упорядоченного бинарного дерева при добавлении элемента Х к другому упорядоченному бинарному дереву формулируется следующим образом.
Граничное условие:
Добавление Х к nil дает бд(nil, Х, nil).
Рекурсивные условия:
При добавлении Х к бд(Лд, К, Пд) нужно рассмотреть два случая, чтобы быть уверенным, что результирующее дерево будет упорядоченным.
Х меньше, чем К. В этом случае нужно добавить Х к Лд, чтобы получить левое поддерево. Правое поддерево равно Пд, а значение корня результирующего дерева равно К.Х больше, чем К. В таком случае нужно добавить Х к Пд, чтобы получить правое поддерево. Левое поддерево равно Лд, а значение корня — К.Такой формулировке задачи соответствует программа:
/* Граничное условие: включ_бд(nil, Х, бд(nil, Х, nil)). /* Рекурсивные условия: /*(1) включ_бд(бд(Лд, К, Пд), Х, бд(Лднов, К, Пд)) :- Х@К, включ_бд(Лд,Х,Лднов). /*(2) включ_бд(бд(Лд, К, Пд), Х, бд(Лд, К, Пднов)) :- Х@К, включ_бд(Пд, Х, Пднов). На запрос ?- включ_бд(nil, d, Т1), включ_бд(Т1, а, Т2). будут получены значения Т1=бд(nil, d, nil) Т2=бд(бд(nil, а, nil), d, nil) Процедуру включ_бд() можно использовать для построения упорядоченного дерева из списка:
/* Граничное условие: список_в_дерево([], nil). /* Рекурсивное условие: список_в_дерево([Н | Т], Бд) :- список_в_дерево(Т, Бд2), включ_бд(Н, Бд2, Бд). Заметим, что включ_бд не обеспечивает построения сбалансированного дерева. Однако существуют алгоритмы, гарантирующие такое построение.
задача поиска пути в лабиринте
В качестве примера использования механизма возврата напишем процедуру для поиска пути в лабиринте. Лабиринт представлен фактами вида:
стена(I, J) для позиции в I-м ряду и J-й колонке, где есть стена отсутств_стена(I, J) для позиции в I-м ряду и J-й колонке, где нет стены выход (I, J) для позиции в 1-м ряду и J-й колонке, являющейся выходомРассмотрим небольшой лабиринт:

Последний ряд лабиринта описывается фактами:
стена(4,1). стена(4,3). стена(4,4). отсутств_стена(4,2).Если задана исходная позиция, путь к выходу можно найти следующим образом.
Граничное условие:
Если исходная позиция является выходом, то путь найден.
Рекурсивные условия:
Ищем путь из исходной позиции в северном направлении. Если пути нет, идем на юг. Если пути нет, идем на запад. Если нельзя, идем на восток. Если соседняя позиция на севере (юге, западе, востоке) является стеной, то нет смысла искать путь из начальной позиции к выходу. Чтобы не ходить кругами, будем вести список позиций, в которых мы побывали.
Изложенному способу решения задачи соответствует процедура путь: она ищет путь (второй аргумент) к выходу из некоторой позиции (первый аргумент). Третьим аргументом является список позиций, где мы побывали.
/* Терм a(I, J) представляет позицию в /* I-м ряду и J-й колонке. /* Нашли путь ? путь(а(I, J),[а(I, J)], Были) :- выход(I, J). /* Пытаемся идти на север путь(а(I, J),[а(I, J) | Р], Были) :- К is I-1, можем_идти(a (K, J), Были), путь(а(I, J) ,Р, [a(K, J) | Были]). /* Пытаемся идти на юг путь(а(I, J),[а(I, J) | Р], Были) :- К is I+1, можем_идти(a (K, J), Были), путь(а(I, J) ,Р, [a(K, J) | Были]). /* Пытаемся идти на запад путь(а (I, J), [a (I, J) | P], Были) :- L is J-1, можем_идти(а(I, L), Были), путь(а(I, L), Р, [а(I, L)| Были]). /* Пытаемся идти на восток путь(а (I, J), [a (I, J) | P], Были) :- L is J+1, можем_идти(а(I, L), Были), путь(а(I, L), Р, [а(I, L)| Были]). /* в позицию a(I, J) можно попасть при /* условии, что там нет стены и мы /* не побывали в ней прежде можем_идти(а(I, J)), Были) :- отсутств_стена(I, J), not (принадлежит (a (I, J), Были)).Чтобы понять, каким образом процедура ищет путь к выходу, рассмотрим процесс согласования запроса с описанием лабиринта, описанного выше:
?-путь(а(4,2), Р, [а(4.2)]).
Выходом из лабиринта является позиция выход (3,1).
Выбор первого утверждения не приводит к согласованию целевого утверждения, поскольку а (4,2) — не выход. Во втором утверждении делается попытка найти путь в северном направлении, т.е. согласовать целевое утверждение
путь(а(3, 2), Р2, [а(3, 2), а(4, 2)]).
Целевое утверждение не удается согласовать с первым утверждением
путь(а(3, 2), Р2, [а(3, 2), а(4, 2)])
так как а (3,2) не является выходом. Во втором утверждении предпринимается попытка найти путь, двигаясь на север, т.е. согласовать целевое утверждение
путь(а(2,2), РЗ, [а(2, 2), а(3, 2), а(4, 2)]).
Ни одно из утверждений не может согласовать
путь(а(2, 2), РЗ, [а(2, 2), а(3, 2), а(4, 2)]).
Первое утверждение — потому, что а (2, 2) не является выходом, второе — потому, что северная позиция является стеной, третье утверждение — потому, что в южной позиции мы уже побывали, а четвертое и пятое утверждения — потому, что западная и восточная границы — это стены.
Неудача в согласовании
путь(а(2, 2), РЗ, [а(2, 2), а(3, 2), а(4, 2)])
заставляет Пролог-систему вернуться в ту точку, где было выбрано второе утверждение при попытке согласовать
путь(а(3, 2), Р2, [а(3, 2), а(4, 2)]).
Решение пересматривается и выбирается третье утверждение.
В третьем утверждении осуществляется попытка найти путь, двигаясь на юг, но она оказывается неудачной, поскольку мы уже побывали в позиции а (4, 2). Тогда, чтобы согласовать
путь(а(3, 2), Р2, [а(3, 2), а(4, 2)]),
выбирается четвертое утверждение. Мы успешно находим путь, двигаясь в западном направлении к позиции а(3,1), которая и является выходом. Рекурсия сворачивается, и в результате получается путь
Р=[а(4, 2),а(3, 2), а(3,1)] другие решения(да/нет)? да Других решений нет Альтернативный путь [a(4,2), a(3,2), a(2,2), a(3,2), a(3,1)] мы получить не можем, потому что не разрешается дважды бывать в одной и той же позиции.
Описанная процедура не обязательно находит кратчайший путь к выходу. Кратчайший путь можно найти, генерируя альтернативные пути с помощью вызова состояния неудачи и запоминая кратчайший из них.
Синтаксический анализ языка и его порождение.
Семантические сети могут помочь парсеру разрешить семантическую неоднозначность. Без такого рода представления вся тяжесть анализ языка падает на синтаксические правила и семантические тесты. Структура же семантической сети ясно показывает, как отдельные концепты соединены между собой. Когда парсер встречает какую-либо неоднозначность, он может использовать семантическую сеть для того, чтобы выбрать тот или иной вариант. При работе с семантическими сетями используется несколько техник парсинга.
Парсинг, в основе которого лежит синтаксис. Работа парсера контролируется грамматикой непосредственных составляющих и операторами построения структур и их тестирования. В то время, как данные на входе анализируются, операторы построения структур создают семантическую сеть, а операторы тестирования проверяют ограничения на частично построенной сети. Если никакие ограничения не найдены, то используемое при этом грамматическое правило отвергается и парсер проверяет другую возможность. Это самый распространенный подход.
Синтаксический анализатор с использованием семантики. Синтаксический анализатор с использованием семантики оперирует также как и парсер, в основе которого лежит синтаксис. Однако он оперирует не с синтаксическими категориями типа группа подлежащего и группа сказуемого, а с концептами высокого уровня типа КОРАБЛЬ и ПЕРЕВОЗИТЬ.
Концептуальный парсинг. Семантическая сеть предсказывает возможные ограничения, которые могут встретится в отношениях между словами, а также прогнозировать слова, которые позже могут встретиться в предложении. Например, глагол давать требует одушевленного агента и а также прогнозирует возможность реципиента и объекта, который будет дан. Шенк был одним из самых активных сторонников концептуального парсинга.
Парсинг, основанный на экспертизе слов. Вследствие существования большого количества неправильных образований в естественном языке, многие люди вместо того, чтобы обращаться к каким-либо универсальным обобщениям, используют специальные словари, представляющих собой совокупность некоторых независимых процедур, которые называются экспертами слов.
Анализ предложения рассматривается как процесс, осуществляемый совместно различными словарными экспертами. Главным сторонником этого подхода был Смол.
Аргументы за и против различных техник парсинга часто основывался не на конкретные данные, а больше на уже устоявшемся мнении. И лишь один проект на практике сравнил несколько видов парсинга — это Язык Семантических Репрезентаций, проект разработанный в Университете Берлина. В течение нескольких лет они создали четыре разных вида парсеров для анализа немецкого языка и его записи на Язык Семантических Репрезентаций, который представляет собой сеть.
Первым парсером был парсер, созданный по подобию концептуального парсера Шенка. Было отмечено, что хотя добавление в его лексикон новых слов было довольно легко, анализ однако мог проводиться только на простых предложениях и только относительных придаточных. Расширить область синтаксической обработки этого парсера оказалось сложной задачей.
Второй парсер был семантически ориентированные расширенные сети перехода. В нем было легче обобщить синтаксис, однако аппарат синтаксиса работал медленнее, чем у первого рассмотренного парсера.
Затем работа велась с парсером словарных экспертов. Здесь легко велась обработка особых случаев, однако разбросанность грамматики между отдельными составляющими делала практически невозможным ее общее понимание, поддержку и модифицирование.
Парсер, который был создан относительно недавно, — это синтаксически ориентированный парсер, основанный на общей грамматике фразовой структуры. Он наиболее систематичен и обобщен и относительно быстр.
Эти результаты в принципе соответствуют мнению других лингвистов: синтаксически ориентированные парсеры наиболее целостны, однако для них необходим определенный набор сетевых операторов для плавного взаимодействия между грамматикой и семантическими сетями.
Порождение языка по семантической сети представляет собой обратный парсинг. Вместо синтаксического анализа некоторй цепочки с целью порождения сети генератор языка производит парсинг сети для получения некоторой цепочки.Существует два варианта порождения языка из семантической сети.
Генератор языка просто следует по сети, превращая концепты в слова, а отношения, указанные рядом с дугами, в отношения естественного языка. Этот метод имеет много ограничений.Подходы, ориентированные на синтаксис контролируют порождение языка с помощью грамматических правил, которые используют сеть для того, чтобы определить, какое следующее правило нужно применить.Однако на практике оба метода имеют много сходств: например, первый способ представляет собой последовательность узлов, которые обрабатываются генератором языка, ориентированным на синтаксис.
Экспертные системы, базовые понятия
Об экспертных системах (ЭС) можно говорить много и сложно. Но наш разговор очень упростится, если мы будем исходить из следующего определения экспертной системы. Экспертная система — это программа (на современном уровне развития человечества), которая заменяет эксперта в той или иной области.
Отсюда вытекает простой вывод — все, что мы изучаем в курсе "Основы проектирования систем с ИИ", конечной целью ставит разработку ЭС. В этой лекции мы остановимся только на некоторых особенностях их построения, которые не затрагиваются в остальных лекциях.
ЭС предназначены, главным образом, для решения практических задач, возникающих в слабо структурированной и трудно формализуемой предметной области. ЭС были первыми системами, которые привлекли внимание потенциальных потребителей продукции искусственного интеллекта.
С ЭС связаны некоторые распространенные заблуждения.
Заблуждение первое: ЭС будут делать не более (а скорее даже менее) того, чем может эксперт, создавший данную систему. Для опровержения данного постулата можно построить самообучающуюся ЭС в области, в которой вообще нет экспертов, либо объединить в одной ЭС знания нескольких экспертов, и получить в результате систему, которая может то, чего ни один из ее создателей не может.
Заблуждение второе: ЭС никогда не заменит человека-эксперта. Уже заменяет, иначе зачем бы их создавали?
Экспертные системы, методика построения
В настоящее время сложилась определенная технология разработки ЭС, которая включает следующие шесть этапов: идентификация, концептуализация, формализация, выполнение, тестирование и опытная эксплуатация.
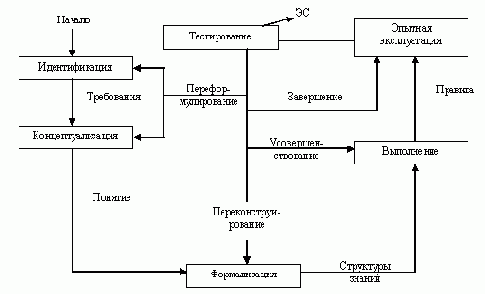
Рис. 9.1. Методика (этапы) разработки ЭС
Экспертные системы, параллельные и последовательные решения
Как мы можем заметить, в большинстве алгоритмов распознавания образов подразумевается, что к началу работы алгоритма уже известна вся входная информация, которая перерабатывается параллельно. Однако ее получение зачастую требует определенных усилий. Да и наши наблюдения за реальными экспертами подтверждают, что зачастую они задают два-три вопроса, после чего делают правильные выводы. Представьте себе, если бы врач (эксперт в области медицины) перед постановкой диагноза "ангина" заставлял бы пациента пройти полное обследование вплоть до кулоноскопии и пункции позвоночника (я не пробовал ни то, ни другое, но думаю, что это малоприятные вещи, а также значительная потеря времени).
Соответственно большинство алгоритмов модифицируются, чтобы обеспечить выполнение следующих условий:
алгоритмы должны работать в условиях неполной информации (последовательно);последовательность запроса информации должна быть оптимальна по критериям быстроты получения результата и (или) наименьшей трудоемкости (болезненности, стоимости и т.д.) получения этой информации.Одной из возможных стратегий для оптимизирования запросов является стратегия получения в первую очередь той информации, которая подтверждает либо опровергает наиболее вероятный на текущий момент результат. Другими словами мы пытаемся подтвердить или опровергнуть наши догадки (обратный вывод).
Этап формализации
Теперь все ключевые понятия и отношения выражаются на некотором формальном языке, который либо выбирается из числа уже существующих, либо создается заново. Другими словами, на данном этапе определяются состав средств и способы представления декларативных и процедурных знаний, осуществляется это представление и в итоге формируется описание решения задачи ЭС на предложенном (инженером по знаниям) формальном языке.
Выходом этапа формализации является описание того, как рассматриваемая задача может быть представлена в выбранном или разработанном формализме. Сюда относится указание способов представления знаний (фреймы, сценарии, семантические сети и т.д.) и определение способов манипулирования этими знаниями (логический вывод, аналитическая модель, статистическая модель и др.) и интерпретации знаний.
Этап идентификации
Этап идентификации связан, прежде всего, с осмыслением тех задач, которые предстоит решить будущей ЭС, и формированием требований к ней. Результатом данного этапа является ответ на вопрос, что надо сделать и какие ресурсы необходимо задействовать (идентификация задачи, определение участников процесса проектирования и их роли, выявление ресурсов и целей).
Обычно в разработке ЭС участвуют не менее трех-четырех человек — один эксперт, один или два инженера по знаниям и один программист, привлекаемый для модификации и согласования инструментальных средств. Также к процессу разработки ЭС могут по мере необходимости привлекаться и другие участники. Например, инженер по знаниям может пригласить других экспертов, чтобы убедиться в правильности своего понимания основного эксперта, представительности тестов, демонстрирующих особенности рассматриваемой задачи, совпадения взглядов различных экспертов на качество предлагаемых решений. Кроме того, для сложных систем считается целесообразным привлекать к основному циклу разработки несколько экспертов. Однако в этом случае, как правило, требуется, чтобы один из экспертов отвечал за непротиворечивость знаний, сообщаемых коллективом экспертов.
Идентификация задачи заключается в составлении неформального (вербального) описания, в котором указываются: общие характеристики задачи; подзадачи, выделяемые внутри данной задачи; ключевые понятия (объекты), их входные (выходные) данные; предположительный вид решения, а также знания, относящиеся к решаемой задаче.
В процессе идентификации задачи инженер по знаниям и эксперт работают в тесном контакте. Начальное неформальное описание задачи экспертом используется инженером по знаниям для уточнения терминов и ключевых понятий. Эксперт корректирует описание задачи, объясняет, как решать ее и какие рассуждения лежат в основе того или иного решения. После нескольких циклов, уточняющих описание, эксперт и инженер по знаниям получают окончательное неформальное описание задачи.
При проектировании ЭС типичными ресурсами являются источники знаний, время разработки, вычислительные средства и объем финансирования.
Для эксперта источниками знаний служат его предшествующий опыт по решению задачи, книги, известные примеры решения задач, а для инженера по знаниям — опыт в решении аналогичных задач, методы представления знаний и манипулирования ими, программные инструментальные средства. При определении времени разработки обычно имеется в виду, что сроки разработки и внедрения ЭС составляют, как правило, не менее года (при трудоемкости 5 чел.-лет). Определение объема финансирования оказывает существенное влияние на процесс разработки, так как, например, при недостаточном финансировании предпочтение может быть отдано не разработке оригинальной новой системы, а адаптации существующей.
При идентификации целей важно отличать цели, ради которых создается ЭС, от задач, которые она должна решать. Примерами возможных целей являются: формализация неформальных знаний экспертов; улучшение качества решений, принимаемых экспертом; автоматизация рутинных аспектов работы эксперта (пользователя); тиражирование знаний эксперта.
Этап концептуализации
На данном этапе проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. Этот этап завершается созданием модели предметной области (ПО), включающей основные концепты и отношения. На этапе концептуализации определяются следующие особенности задачи: типы доступных данных; исходные и выводимые данные, подзадачи общей задачи; применяемые стратегии и гипотезы; виды взаимосвязей между объектами ПО, типы используемых отношений (иерархия, причина — следствие, часть — целое и т.п.); процессы, применяемые в ходе решения; состав знаний, используемых при решении задачи; типы ограничений, накладываемых на процессы, которые применены в ходе решения; состав знаний, используемых для обоснования решений.
Существует два подхода к процессу построения модели предметной области, которая является целью разработчиков ЭС на этапе концептуализации. Признаковый или атрибутивный подход предполагает наличие полученной от экспертов информации в виде троек объект—атрибут—значение атрибута, а также наличие обучающей информации. Этот подход развивается в рамках направления, получившего название "формирование знаний" или "машинное обучение" (machine learning).
Второй подход, называемый структурным (или когнитивным), осуществляется путем выделения элементов предметной области, их взаимосвязей и семантических отношений.
Для атрибутивного подхода характерно наличие наиболее полной информации о предметной области: об объектах, их атрибутах и о значениях атрибутов. Кроме того, существенным моментом является использование дополнительной обучающей информации, которая задается группированием объектов в классы по тому или иному содержательному критерию. Тройки объект—атрибут—значение атрибута могут быть получены с помощью так называемого метода реклассификации, который основан на предположении что задача является объектно-ориентированной и объекты задачи хорошо известны эксперту. Идея метода состоит в том, что конструируются правила (комбинации значений атрибутов), позволяющие отличить один объект от другого.
Обучающая информация может быть задана на основании прецедентов правильных экспертных заключений, например, с помощью метода извлечения знаний, получившего название "анализ протоколов мыслей вслух".
При наличии обучающей информации для формирования модели предметной области на этапе концептуализации можно использовать весь арсенал методов, развиваемых в рамках задачи распознавания образов. Таким образом, несмотря на то, что здесь атрибутивному подходу не уделено много места, он является одним из потребителей всего того, что было указано в лекции, посвященной распознаванию образов и автоматического группирования данных.
Структурный подход к построению модели предметной области предполагает выделение следующих когнитивных элементов знаний: 1. Понятия. 2. Взаимосвязи. 3. Метапонятия. 4. Семантические отношения.
Выделяемые понятия предметной области должны образовывать систему, под которой понимается совокупность понятий, обладающая следующими свойствами: уникальностью (отсутствием избыточности); полнотой (достаточно полным описанием различных процессов, фактов, явлений и т.д. предметной области); достоверностью (валидностью — соответствием выделенных единиц смысловой информации их реальным наименованиям) и непротиворечивостью (отсутствием омонимии).
При построении системы понятий с помощью "метода локального представления" эксперта просят разбить задачу на подзадачи для перечисления целевых состояний и описания общих категорий цели. Далее для каждого разбиения (локального представления) эксперт формулирует информационные факты и дает им четкое наименование (название). Считается, что для успешного решения задачи построения модели предметной области число таких информационных фактов в каждом локальном представлении, которыми человек способен одновременно манипулировать, должно быть примерно равно семи.
"Метод вычисления коэффициента использования" основан на следующей гипотезе. Элемент данных (или информационный факт) может являться понятием, если он:
используется в большом числе подзадач;используется с большим числом других элементов данных;редко используется совместно с другими элементами данных по сравнению с общим числом его применения во всех подзадачах (это и есть коэффициент использования).Полученные значения могут служить критерием для классификации всех элементов данных и, таким образом, для формирования системы понятий.
"Метод формирования перечня понятий" заключается в том, что экспертам (желательно, чтобы их было больше двух) дается задание составить список понятий, относящихся к исследуемой предметной области. Понятия, выделенные всеми экспертами, включаются в систему понятий, остальные подлежат обсуждению.
"Ролевой метод" состоит в том, что эксперту дается задание обучить инженера по знаниям решению некоторых задач предметной области. Таким образом, эксперт играет роль учителя, а инженер по знаниям — роль ученика. Процесс обучения записывается на магнитофон. Затем третий участник прослушивает магнитофонную ленту и выписывает на бумаге все понятия, употребленные учителем или учеником.
При использовании метода "составления списка элементарных действий" эксперту дается задание составить такой список при решении задачи в произвольном порядке.
В методе "составление оглавления учебника" эксперту предлагается представить ситуацию, в которой его попросили написать учебник. Необходимо составить на бумаге перечень предполагаемых глав, разделов, параграфов, пунктов и подпунктов книги.
"Текстологический метод" формирования системы понятий заключается в том, что эксперту дается задание выписать из руководств (книг по специальности) некоторые элементы, представляющие собой единицы смысловой информации.
Группа методов установления взаимосвязей предполагает установление семантической близости между отдельными понятиями. В основе установления взаимосвязей лежит психологический эффект "свободных ассоциаций", а также фундаментальная категория близости объектов или концептов.
Эффект свободных ассоциаций заключается в следующем. Испытуемого просят отвечать на заданное слово первым пришедшим на ум словом. Как правило, реакция большинства испытуемых (если слова не были слишком необычными) оказывается одинаковой. Количество переходов в цепочке может служить мерой "смыслового расстояния" между двумя понятиями. Многочисленные опыты подтверждают гипотезу, что для двух любых слов (понятий) существует ассоциативная цепочка, состоящая не более чем из семи слов.
"Метод свободных ассоциаций" основан на психологическом эффекте, описанном выше. Эксперту предъявляется понятие с просьбой назвать как можно быстрее первое пришедшее на ум понятие из сформированной ранее системы понятий. Далее производится анализ полученной информации.
В методе "сортировка карточек" исходным материалом служат выписанные на карточки понятия. Применяются два варианта метода. В первом эксперту задаются некоторые глобальные критерии предметной области, которыми он должен руководствоваться при раскладывании карточек на группы. Во втором случае, когда сформулировать глобальные критерии невозможно, эксперту дается задание разложить карточки на группы в соответствии с интуитивным пониманием семантической близости предъявляемых понятий.
"Метод обнаружения регулярностей" основан на гипотезе о том, что элементы цепочки понятия, которые человек вспоминает с определенной регулярностью, имеют тесную ассоциативную взаимосвязь. Для эксперимента произвольным образом отбирается 20 понятий. Эксперту предъявляется одно из числа отобранных. Процедура повторяется до 20 раз, причем каждый раз начальные концепты должны быть разными. Затем инженер по знаниям анализирует полученные цепочки с целью нахождения постоянно повторяющихся понятий (регулярностей). Внутри выделенных таким образом группировок устанавливаются ассоциативные взаимосвязи.
Кроме рассмотренных выше неформальных методов для установления взаимосвязей между отдельными понятиями применяются также формальные методы.
Сюда в первую очередь относятся методы семантического дифференциала и репертуарных решеток.
Выделенные понятия предметной области и установленные между ними взаимосвязи служат основанием для дальнейшего построения системы метапонятий — осмысленных в контексте изучаемой предметной области системы группировок понятий. Для определения этих группировок применяют как неформальные, так и формальные методы.
Интерпретация, как правило, легче дается эксперту, если группировки получены неформальными методами. В этом случае выделенные классы более понятны эксперту. Причем в некоторых предметных областях совсем не обязательно устанавливать взаимосвязи между понятиями, так как метапонятия, образно говоря, "лежат на поверхности".
Последним этапом построения модели предметной области при концептуальном анализе является установление семантических отношений между выделенными понятиями и метапонятиями. Установить семантические отношения — это значит определить специфику взаимосвязи, полученной в результате применения тех или иных методов. Для этого необходимо каждую зафиксированную взаимосвязь осмыслить и отнести ее к тому или иному типу отношений.
Существует около 200 базовых отношений, например, "часть — целое", "род — вид", "причина — следствие", пространственные, временные и другие отношения. Для каждой предметной области помимо общих базовых отношений могут существовать и уникальные отношения.
"Прямой метод" установления семантических отношений основан на непосредственном осмыслении каждой взаимосвязи. В том случае, когда эксперт затрудняется дать интерпретацию выделенной взаимосвязи, ему предлагается следующая процедура. Формируются тройки: понятие 1 — связь — понятие 2. Рядом с каждой тройкой записывается короткое предложение или фраза, построенное так, чтобы понятие 1 и понятие 2 входили в это предложение. В качестве связок используются только содержательные отношения и не применяются неопределенные связки типа "похож на" или "связан с".
Для " косвенного метода" не обязательно иметь взаимосвязи, достаточно лишь наличие системы понятий. Формулируется некоторый критерий, для которого из системы понятий выбирается определенная совокупность концептов. Эта совокупность предъявляется эксперту с просьбой дать вербальное описание сформулированного критерия. Концепты предъявляются эксперту все сразу (желательно на карточках). В случае затруднений эксперта прибегают к разбиению отобранных концептов на группы с помощью более мелких критериев. Исходное количество концептов может быть произвольным, но после разбиения на группы в каждой из таких групп должно быть не более десяти концептов. После того как составлены описания по всем группам, эксперту предлагают объединить эти описания в одно.
Следующий шаг в косвенном методе установления семантических отношений — это анализ текста, составленного экспертом. Концепты заменяют цифрами (это может быть исходная нумерация), а связки оставляют. Тем самым строится некоторый граф, вершинами которого служат концепты, а дугами — связки (например, "ввиду", "приводит к", "выражаясь с одной стороны", "обусловливая", "сочетаясь", "определяет", "вплоть до" и т.д.) Этот метод позволяет устанавливать не только базовые отношения, но и отношения, специфические для конкретной предметной области.
Рассмотренные выше методы формирования системы понятий и метапонятий, установления взаимосвязей и семантических отношений в разных сочетаниях применяются на этапе концептуализации при построении модели предметной области.
Этап опытной эксплуатации
На этом этапе проверяется пригодность ЭС для конечного пользователя. Пригодность ЭС для пользователя определяется в основном удобством работы с ней и ее полезностью. Под полезностью ЭС понимается ее способность в ходе диалога определять потребности пользователя, выявлять и устранять причины неудач в работе, а также удовлетворять указанные потребности пользователя (решать поставленные задачи). В свою очередь, удобство работы с ЭС подразумевает естественность взаимодействия с ней (общение в привычном, не утомляющем пользователя виде), гибкость ЭС (способность системы настраиваться на различных пользователей, а также учитывать изменения в квалификации одного и того же пользователя) и устойчивость системы к ошибкам (способность не выходить из строя при ошибочных действиях неопытного пользователях).
В ходе разработки ЭС почти всегда осуществляется ее модификация. Выделяют следующие виды модификации системы: переформулирование понятий и требований, переконструирование представления знаний в системе и усовершенствование прототипа.
Этап тестирования
В ходе данного этапа производится оценка выбранного способа представления знаний в ЭС в целом. Для этого инженер по знаниям подбирает примеры, обеспечивающие проверку всех возможностей разработанной ЭС.
Различают следующие источники неудач в работе системы: тестовые примеры, ввод-вывод, правила вывода, управляющие стратегии.
Показательные тестовые примеры являются наиболее очевидной причиной неудачной работы ЭС. В худшем случае тестовые примеры могут оказаться вообще вне предметной области, на которую рассчитана ЭС, однако чаще множество тестовых примеров оказывается слишком однородным и не охватывает всю предметную область. Поэтому при подготовке тестовых примеров следует классифицировать их по подпроблемам предметной области, выделяя стандартные случаи, определяя границы трудных ситуаций и т.п.
Ввод-вывод характеризуется данными, приобретенными в ходе диалога с экспертом, и заключениями, предъявленными ЭС в ходе объяснений. Методы приобретения данных могут не давать требуемых результатов, так как, например, задавались неправильные вопросы или собрана не вся необходимая информация. Кроме того, вопросы системы могут быть трудными для понимания, многозначными и не соответствующими знаниям пользователя. Ошибки при вводе могут возникать также из-за неудобного для пользователя входного языка. В ряде приложения для пользователя удобен ввод не только в печатной, но и в графической или звуковой форме.
Выходные сообщения (заключения) системы могут оказаться непонятны пользователю (эксперту) по разным причинам. Например, их может быть слишком много или, наоборот, слишком мало. Также причиной ошибок может являться неудачная организация, упорядоченность заключений или неподходящий пользователю уровень абстракций с непонятной ему лексикой.
Наиболее распространенный источник ошибок в рассуждениях находится в правилах вывода. Важная причина здесь часто кроется в отсутствии учета взаимозависимости сформированных правил. Другая причина заключается в ошибочности, противоречивости и неполноте используемых правил.
Если неверна посылка правила, то это может привести к употреблению правила в неподходящем контексте. Если ошибочно действие правила, то трудно предсказать конечный результат. Правило может быть ошибочно, если при корректности его условия и действия нарушено соответствие между ними.
Нередко к ошибкам в работе ЭС приводят применяемые управляющие стратегии. Изменение стратегии бывает необходимо, например, если ЭС анализирует сущности в порядке, отличном от "естественного" для эксперта. Последовательность, в которой данные рассматриваются ЭС, не только влияет на эффективность работы системы, но и может приводить к изменению конечного результата. Так, рассмотрение правила А до правила В способно привести к тому, что правило В всегда будет игнорироваться системой. Изменение стратегии бывает также необходимо и в случае неэффективной работы ЭС. Кроме того, недостатки в управляющих стратегиях могут привести к чрезмерно сложным заключениям и объяснениям ЭС.
Критерии оценки ЭС зависят от точки зрения. Например, при тестировании ЭС-1 главным в оценке работы системы является полнота и безошибочность правил вывода. При тестировании промышленной системы превалирует точка зрения инженера по знаниям, которого в первую очередь интересует вопрос оптимизации представления и манипулирования знаниями. И, наконец, при тестировании ЭС после опытной эксплуатации оценка производится с точки зрения пользователя, заинтересованного в удобстве работы и получения практической пользы
Этап выполнения
Цель этого этапа — создание одного или нескольких прототипов ЭС, решающих требуемые задачи. Затем на данном этапе по результатам тестирования и опытной эксплуатации создается конечный продукт, пригодный для промышленного использования. Разработка прототипа состоит в программировании его компонентов или выборе их из известных инструментальных средств и наполнении базы знаний.
Главное в создании прототипа заключается в том, чтобы этот прототип обеспечил проверку адекватности идей, методов и способов представления знаний решаемым задачам. Создание первого прототипа должно подтвердить, что выбранные методы решений и способы представления пригодны для успешного решения, по крайней мере, ряда задач из актуальной предметной области, а также продемонстрировать тенденцию к получению высококачественных и эффективных решений для всех задач предметной области по мере увеличения объема знаний.
После разработки первого прототипа ЭС-1 круг предлагаемых для решения задач расширяется, и собираются пожелания и замечания, которые должны быть учтены в очередной версии системы ЭС-2. Осуществляется развитие ЭС-1 путем добавления "дружественного" интерфейса, средств для исследования базы знаний и цепочек выводов, генерируемых системой, а также средств для сбора замечаний пользователей и средств хранения библиотеки задач, решенных системой.
Выполнение экспериментов с расширенной версией ЭС-1, анализ пожеланий и замечаний служат отправной точкой для создания второго прототипа ЭС-2. Процесс разработки ЭС-2 — итеративный. Он может продолжаться от нескольких месяцев до нескольких лет в зависимости от сложности предметной области, гибкости выбранного представления знаний и степени соответствия управляющего механизма решаемым задачам (возможно, потребуется разработка ЭС-3 и т.д.). При разработке ЭС-2, кроме перечисленных задач, решаются следующие:
анализ функционирования системы при значительном расширении базы знаний;исследование возможностей системы в решении более широкого круга задач и принятие мер для обеспечения таких возможностей;анализ мнений пользователей о функционировании ЭС;разработка системы ввода-вывода, осуществляющей анализ или синтез предложений ограниченного естественного языка, позволяющей взаимодействовать с ЭС-2 в форме, близкой к форме стандартных учебников для данной области.Если ЭС-2 успешно прошла этап тестирования, то она может классифицироваться как промышленная экспертная система.
Пример ЭС, основанной на правилах логического вывода и действующую в обратном порядке
Допустим, вы хотите построить ЭС в области медицинской диагностики. В этом случае вам вряд ли нужно строить систему, использующую обучение на примерах, потому что имеется большое количество доступной информации, позволяющей непосредственно решать такие проблемы. К сожалению, эта информация приведена в неподходящем для обработки на компьютере виде.
Возьмите медицинскую энциклопедию и найдите в ней статью, например, о гриппе. Вы обнаружите, что в ней приведены все симптомы, причем они бесспорны. Другими словами, при наличии указанных симптомов всегда можно поставить точный диагноз.
Но чтобы использовать информацию, представленную в таком виде, вы должны обследовать пациента, решить, что у него грипп, а потом заглянуть в энциклопедию, чтобы убедиться, что у него соответствующие симптомы. Что-то здесь не так. Ведь необходимо, чтобы вы могли обследовать пациента, решить, какие у него симптомы, а потом по этим симптомам определить, чем он болен. Энциклопедия же, похоже, не позволяет сделать это так, как надо. Нам нужна не болезнь со множеством симптомов, а система, представляющая группу симптомов с последующим названием болезни. Именно это мы сейчас и попробуем сделать.
Идеальной будет такая ситуация, при которой мы сможем в той или иной области предоставить машине в приемлемом для нее виде множество определений, которые она сможет использовать примерно так же, как человек-эксперт. Именно это и пытаются делать такие программы, как PUFF, DENDRAL, PROSPECTOR.
С учетом байесовской системы логического вывода примем, что большая часть информации не является абсолютно точной, а носит вероятностный характер. Итак, начнем программирование:
| № | Симптомы |
| 1 | Симптом_1 |
| 2 | Симптом_2 |
| N | Симптом_N |
Полученный формат данных мы будем использовать для хранения симптомов. При слове "симптомы" создается впечатление, что мы связаны исключительно с медициной, хотя речь может идти о чем угодно. Суть в том, что компьютер задает множество вопросов, содержащихся в виде символьных строк <Симптом_1>, <Симптом_2> и т.д.
Например, Симптом_1 может означать строку "Много ли вы кашляете?", или, если вы пытаетесь отремонтировать неисправный автомобиль, — строку "Ослаб ли свет фар?".
Теперь оформим болезни:
| № | Болезнь | p | [j, py, pn] |
| 1 | Болезнь_1 | p1 | [j, py, pn]1 |
| 2 | Болезнь_2 | p2 | [j, py, pn]2 |
| N | Болезнь_N | pn | [j, py, pn]n |
Поле "болезнь" характеризует название возможного исхода, например "Грипп". Следующее поле — p — это априорная вероятность такого исхода P(H), т.е. вероятность исхода в случае отсутствия дополнительной информации. После этого идет ряд повторяющихся полей из трех элементов. Первый элемент — j — это номер соответствующего симптома (свидетельства, переменной, вопроса, если вы хотите назвать его по-другому). Следующие два элемента — P(E : H) и P(E : не H) — соответственно вероятности получения ответа "Да" на этот вопрос, если возможный исход верен и неверен. Например:
| 2010 | Грипп | 0.01 | (1, 0.9, 0.01); (2, 1, 0.01); (3, 0, 0.01) |
Допустим, программа задает вопрос 1 (симптом 1). Тогда мы имеем P(E : H)=0.9 и P(E : не H)=0.01, а это означает, что если у пациента грипп, то он в девяти случаях из десяти ответит "да" на этот вопрос, а если у него нет гриппа, он ответит "да" лишь в одном случае из ста. Очевидно, ответ "да" подтверждает гипотезу о том, что у него грипп. Ответ "нет" позволяет предположить, что человек гриппом не болеет.
Так же и во второй группе симптомов (2, 1, 0.01). В этом случае P(E : H)=0.9, т.е. если у человека грипп, то этот симптом должен присутствовать. Соответствующий симптом может существовать и при отсутствии гриппа (P(E : не H)=0.01), но это маловероятно.
Вопрос 3 исключает грипп при ответе "да", потому что P(E : H)=0. Это может быть вопрос вроде такого: "наблюдаете ли вы такой симптом на протяжении большей части жизни?" — или что-нибудь вроде этого.
Нужно подумать, — а если вы хотите получить хорошие результаты, то и провести исследование, — чтобы установить обоснованные значения для этих вероятностей. И если быть честным, то получение такой информации — вероятно, труднейшая задача, в решении которой компьютер также сможет существенно помочь Вам. Если вы напишите программу общего назначения, ее основой будет теорема Байеса, утверждающая:
P(H : E) = P(E : H) * P(H) / (P(E : H) * P(H) +P(E : не H) * P(не H).
Вероятность осуществления некой гипотезы H при наличии определенных подтверждающих свидетельств Е вычисляется на основе априорной вероятности этой гипотезы без подтверждающих свидетельств и вероятности осуществления свидетельств при условиях, что гипотеза верна или неверна.
Поэтому, возвращаясь к нашим болезням, увидим:
P(H : E) = py * p / (py * p + pn * (1 - p)) .
В данном случае мы начинаем с того, что Р(Н) = р для всех болезней. Программа задает соответствующий вопрос и в зависимости от ответа вычисляет P(H : E). Ответ "да" подтверждает вышеуказанные расчеты, ответ "нет" тоже, но с (1 – py) вместо py и (1 – pn) вместо pn. Сделав так, мы забываем об этом, за исключением того, что априорная вероятность P(H) заменяется на P(H : E). Затем продолжается выполнение программы, но с учетом постоянной коррекции значения P(H) по мере поступления новой информации.
Описывая алгоритм, мы можем разделить программу на несколько частей.
Часть 1.
Ввод данных.
Часть 2.
Просмотр данных на предмет нахождения априорной вероятности P(H). Программа вырабатывает некоторые значения массива правил и размещает их в массиве RULEVALUE. Это делается для того, чтобы определить, какие вопросы (симптомы) являются самыми важными, и выяснить, о чем спрашивать в первую очередь. Если вы вычислите для каждого вопроса RULEVALUE[I] = RULEVALUE[I] + ABS (P(H : E) – P(H : не E)), то получите значения возможных изменений вероятностей всех болезней, к которым они относятся.
Часть 3.
Программа находит самый важный вопрос и задает его. Существует ряд вариантов, что делать с ответом: вы можете просто сказать: "да" или "нет". Можете попробовать сказать "не знаю", — изменений при этом не произойдет. Гораздо сложнее использовать шкалу от –5 до +5, чтобы выразить степень уверенности в ответе.
Часть 4.
Априорные вероятности заменяются новыми значениями при получении новых подтверждающих свидетельств.
Часть 5.
Подсчитываются новые значения правил. Определяются также минимальное и максимальное значения для каждой болезни, основанные на существующих в данный момент априорных вероятностях и предположениях, что оставшиеся свидетельства будут говорить в пользу гипотезы или противоречить ей. Важно выяснить: стоит ли данную гипотезу продолжать рассматривать или нет? Гипотезы, которые не имеют смысла, просто отбрасываются. Те же из них, чьи минимальные значения выше определенного уровня, могут считаться возможными исходами. После этого возвращаемся к части 3.
